
Mixpanel 的主要撑捏之一是咱们额外的列式存储数据库ARB,它是咱们成心为繁盛客户需求而盘算的。在这篇博文中,咱们深刻盘问了浮现认知列式文献的事件读取器代码的全面重写。主要谋划是权臣提高查询性能,异常是对于那些具有遴荐性过滤器的查询性能。
鉴于新的综合与旧的综合有很大不同,咱们收拢这个契机从 C 迁徙到 C++,以罢了代码库的当代化。跟着 V2 阅读器的引入,查询速率平均提高了 12%,一些较慢的查询速率提高了 75%。
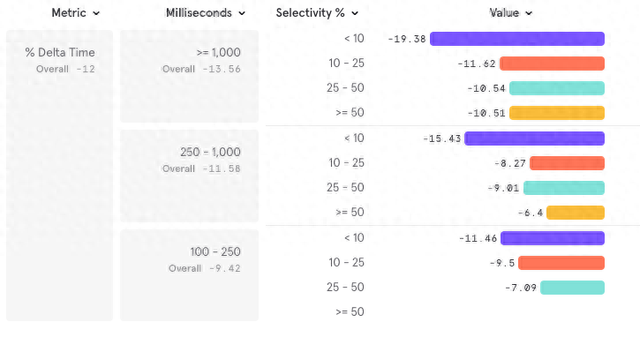
速率较慢且遴荐性较强的查询从 V2 罢了中获益最多
阅读器 V1
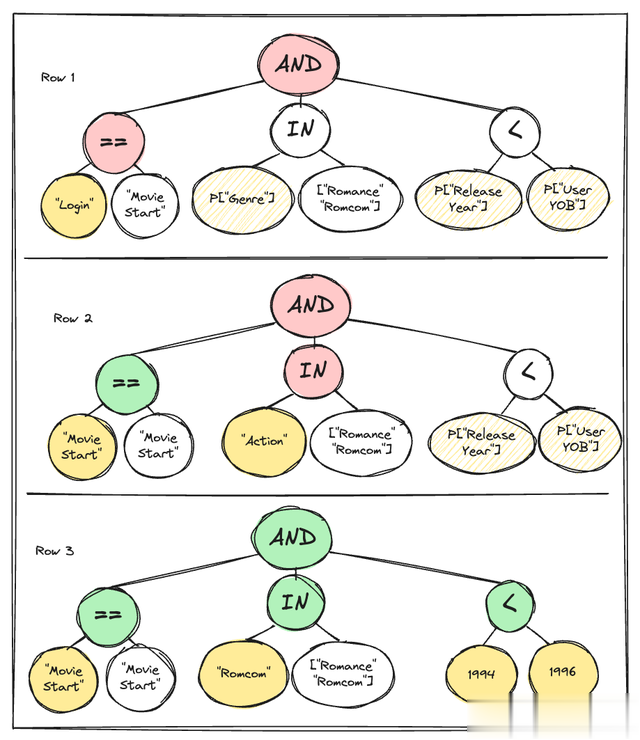
假定有一位流媒体劳动 Mixpanel 客户想要查找用户在降生前不雅看放纵电影的次数。平淡,用户的降生年份是从用户个东说念主尊府中获取的,电影年份和类型是从按电影称号/ID 查找的表中获取的。但是,为了简便起见,咱们暂时假定它们仅仅事件属性。给定过滤器的 eval 节点(用于暗示遴荐器抒发式的递归树状结构)如下所示:
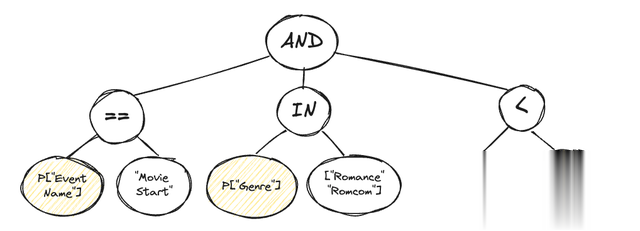
过滤器的根节点恒久输出布尔值。属性评估节点以黄色隆起清醒
在 V1 中,ARB 读取器最初通过文献内存映射 (mmap) 加载过滤器评估所需的通盘列。然后,它不时为每个加载的列实例化列光标对象。随后,ARB 读取器一次一个事件地遍历数据,并相应地激动光标。对于每个事件,ARB 读取器从列中检索相应的值并将它们转发到过滤器的评估节点。该评估节点反过来会产生一个布尔输出,凭证评估收尾细目是否应包括或打消该事件。在包含后,事件将传递给特定的查询代码,该代码凭证查询类型(瞻念察、漏斗、历程等)进行进一步处理。不管电影类型是否为爱情片,读取器齐会将刊行年份和用户降生年份的值从文献加载到内存中。您也曾不错启动了解若何提高遵守。
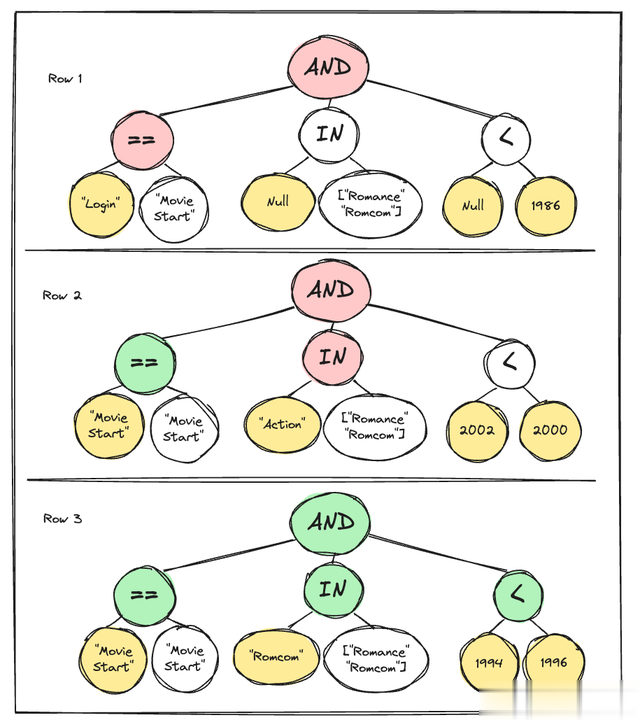
不管其父级评估节点是否被评估,属性评估节点齐会被评估
阅读器 V2
1- 谓词下推
谓词下推的主要想想是将“property[x]”评估节点的过早评估下推,直到骨子需要它们为止,以幸免不消要隘从文献中加载列值。为了罢了这少量,咱们将评估节点树办法为子树,这些子树的根节点评估为不错通过 AND 或 OR 组合的布尔值。然后,每个最小的子树将浮现其本身属性的列游标,仅在需要时增多它们。
仅当其父节点得到评估时,才会评估属性评估节点。
2- 批处理和 CPU 缓存
ARB 读取器使用 mmap 造访文献的数据,因此为了提高数据造访的缓存掷中率,最佳先从一列读取尽可能多的数据,然后再从下一列读取。新的代码架构允许咱们这么作念。咱们不会一次评估一滑的通盘树,而是先评估一批行中与单个列相关的每个子树,然后再参加下一个子树。唯唯独批中仍需要进一步评估的行范畴才会传递到下一个子树。举例,若是子树的根是“AND”节点,则唯独评估为确凿范畴才会传递给背面的子树进行评估。违反,若是它们的根是“OR”节点,则唯独评估为假的范畴才会传递。此外,若是跳过的事件数目饱胀大,这种次第不错使列光标前进到列中的下一个查验点。由于值的大小可变,咱们不可老是索引到列中的所需事件。因此,咱们存储时时的查验点以快速跳过。
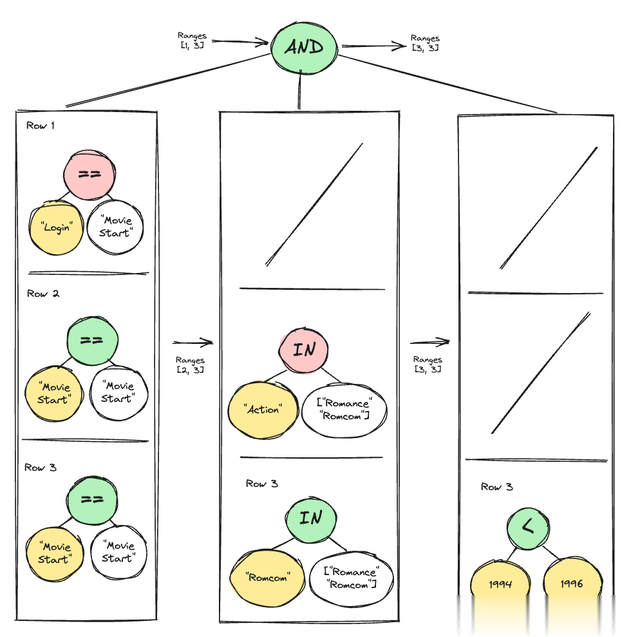
在每个节点上,打消范畴均乌有行任何责任
3-重叠编码
在列方法中,若是某一滑中好多事件的值疏通,咱们只会存储该值一次,然后使用特殊编码来指定该值重叠的次数。这是一种常见的压缩计谋。新的架构以批量神气处理列,通过使用重叠编码跳过具有疏通值的连气儿行,从而幸免冗余评估,从而提高遵守。
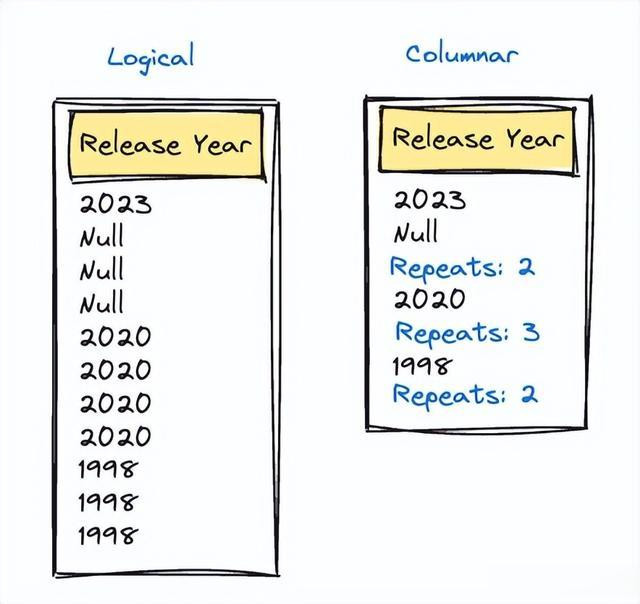
咱们使用重叠编码来压缩相通的连气儿值
4- 评估节点缓存
一些最悉力的单属性评估节点触及字符串,举例 Lower(Event[“genre”]) in [“romance”, “romcom”, “action“, “Drama”, “thriller”] 需要最初复制小写的字符串,然后进行五次字符串比较。鉴于字符串列平淡浮现出低基数,平淡对应于国度、州、品牌或电影类型等类别,在咱们的列方法中,咱们将特定列的通盘字符串合并到字典中,并在列的数据部分中使用字典索引(检察咱们对于列字典的博客著作)。为了幸免对解除个国度/地区筹备数万次此评估节点,若是属性的值是字符串,咱们会缓存收尾。咱们使用两个位向量来实行此操作,第一个用于它是否之前被评估过,第二个用于评估收尾;两者齐由字符串的字典索引索引。除了最小化评估除外,这还最小化了字典索引到字符串的查找。这仅在评估节点子树只需要一个属性时才有用。对于依赖于多个属性(举例 property[“origin”] == property[“destination”])的子树,情况会变得复杂,因为评估收尾由字典索引缓存。咱们将尝试鄙人一节中措置这个问题。咱们幸免缓存其他值类型有两个原因。最初,位向量不适用于无界值。其次,天然哈希映射是一种遴荐,但它们很悉力,尤其是与单属性评估节点比拟时。
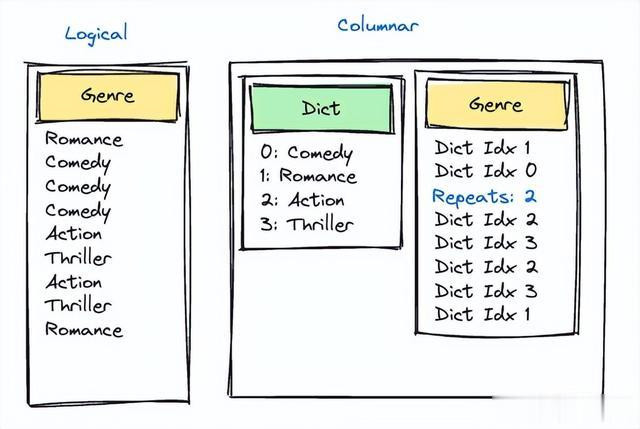
咱们在列的数据部分径直使用字典索引,而不是字符串
5- 多属性评估节点缓存
平淡,Mixpanel 上最慢的查询是具有最复杂过滤器的查询:过滤器包含好多多属性评估节点子树,这些子树无法无为从往常的性能立异中受益。因此,咱们决定尝试为多属性评估节点子树添加评估节点缓存,尽管从表面上讲,缓存的基数可能太高,因此莫得任何克己,但骨子上它后果很好。它高度依赖于数据时局和过滤器时局。
在许厚情况下,过滤器中的列并非统共孤独。举例,让咱们设想一个查询,该查询过滤所不雅看的电影或电视节主张评分高于 7.5。若是是电影,则从电影查找表中索要评分,不然凭证节目称号和季数从节目查找表中索要评分。

该子树无法进一步细分,它取决于三个唯一属性:类型、称号、季节
您很快就能看出,此高下文中的基数并不太高:name 属性将恒久保捏疏通类型,而 season 属性仅出当今献艺中。因此,评估总额远远低于这三个属性基数的乘积。这种类型的过滤情况卓越常见。
由于在这种情况下无法使用位向量,因此咱们遴荐基于这些属性的字典索引(而不是它们的骨子字符串)的聚拢来罢了缓存,并使用平面哈希图。由于这些类型的过滤器的筹备本钱很高,因此在这里使用映射是值得的。为了珍摄在基数过高的情况下产生不消要的支出(不管是内存照旧 CPU),咱们会比及缓存映射集合了 10k 个条款,此时咱们会评估其缓存掷中率。若是觉得后果不够好,咱们会住手使用和填充它。
咱们进行了一项现实,将此分支与主分支进行比较,以考据咱们对于基数的假定。收尾清醒,使用多属性过滤器缓存的查询的缓存掷中率高达 94%,同期性能提高了 21%。尽管唯唯独小部分查询赢得了这种克己,但值得珍摄的是,这些查询齐是最慢的查询之一。因此,事实讲授实施缓存是值得的,因为咱们的谋划是平均蔓延和尾部蔓延。
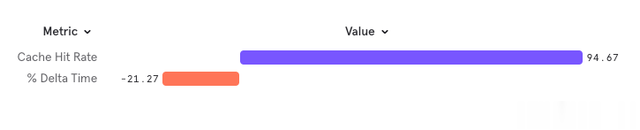
仅清醒具有愚弄多属性评估节点缓存的过滤器的查询的收尾
改日责任
除了这些权臣的性能增强除外,咱们还对代码库进行了模块化和当代化改革,从而打消了多半的本事债务。但是,仍有充足的契机进一步立异。举例,预处理过滤器并以更优化的时局重写它们。最具遴荐性的评估节点子树不错出动为“AND”节点的第一个子节点和“OR”节点的终末一个子节点,从而最大罢休地减少评估的总额。此外,不错从头罗列某些过滤器以确保每个子树唯唯独个属性评估节点,从而最大罢休地浮现 V2 读取器的上风。举例,不错从头罗列前边提到的过滤器以最小化在每个评估节点子树中找到的唯一属性的数目:
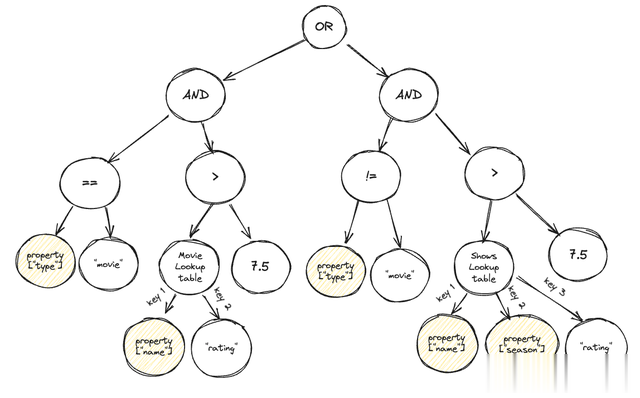
过滤器被疗养为 AND 和 OR 的节点,每个子树大多具有单个属性。
作家:John Mikhail